
ブログのHTMLには、Googleに検索されやすいようにそれぞれの見出しにキーワード情報が含まれています。ブログ内でのタイトルはそれだけ重要な情報が含まれています。本記事では、Pythonの自動スクレイピングを学び、ブログ内のタイトルを抽出する方法を解説します。
 管理人
管理人本記事の読者層は以下の方を想定しています。
- SEO対策のためのスタートアップについて知りたい方
Pythonを利用したスクレイピングの基礎
スクレイピング (scraping)とはWEBサイトのHTMLページ内から必要とする情報を抽出する方法です。これらの抽出した情報から記事を改善することでSEO対策にもなります。
本記事では、一般的なWordPressのブログ記事からタイトル・見出し情報を抽出する方法を学びます。
ここではスクレイピングの実用解析コードを開示します。中でも人気のあるBeautul Soupというモジュールライブラリを利用して実際のブログURLを入力すればタイトルが抽出できるコードを作っていきます。
Python解析コード
Python3で今回使用するモジュールを以下のようにインストールしておきます。
$pip3 install BeautifulSoup
$pip3 install pandas詳しいpip3の使い方(インストール方法など)は以下の記事をご参照ください。

以下に「URL」を記載すると、ブログ記事のタイトル (H1, H2, H3見出し) を抽出するPythonプログラムコードを載せておきます。
下記のURL部分に、実際のブログのURLを貼り付ければ動きます。
import requests
import pandas as pd
from bs4 import BeautifulSoup
html=requests.get("URL").text #URLにタイトルを抽出したい任意のURLページを記載。
original_soup=BeautifulSoup(html,"html.parser")
soup = original_soup.find("main")
#H1:見出しすべて抜き出し
print('---- H1 ----')
M1=soup.find_all("h1")
for element1 in soup.find_all("h1"):
print(element1.text,"(length =",len(element1.text),")")
#H2:見出しすべて抜き出し
print('---- H2 ----')
M2=soup.find_all("h2")
for element2 in soup.find_all("h2"):
print(element2.text,"(length =",len(element2.text),")")
#H3:見出しすべて抜き出し
print('---- H3 ----')
M3=soup.find_all("h3")
for element3 in soup.find_all("h3"):
print(element3.text,"(length =",len(element3.text),")")コードの解説
html=requests.get("URL").text #URLにタイトルを抽出したい任意のURLページを記載。これでテキスト形式でURLないのHTMLのソースファイルが取得できます。
soup = original_soup.find("main")これでhtmlソースファイル内の<main></main>記事の部分を抜き出し「soup」に保存します。
M2=soup.find_all("h2")「soup」から<h2></h2>内の見出しタイトルをすべてを「M2」に配列として保存します。
for element2 in soup.find_all("h2"):ここでelement2内にM2配列に保存したタイトルを入れ込んでprintさせます。
以上です。一度、走らせてみてください。
タイトル自動取得の結果
以下のPythonの解析結果は
本ブログサイト、URL=https://wisenetwork.net/archives/34
で確認してみました。
実際の結果は以下の通りです。
---- H1 ----
中古PCをサーバー化しよう 〜10年落ちでも現役で使える激安お勧め中古PC・サーバー機の選び方〜 (length = 48 )
---- H2 ----
サーバー機で何ができるか? (length = 13 )
どんなパソコンがサーバー機として利用できるのか? (length = 24 )
中古PCを活用しよう (length = 10 )
法人中古のサーバー機を活用しよう (length = 16 )
お値打ちサーバーの選び方 (length = 12 )
まとめ (length = 3 )
関連リンク (length = 5 )
---- H3 ----
小型サーバー機:玄箱 (Kuro-Box) (length = 21 )
超小型サーバー機:ラズパイ (Raspberry-Pi) (length = 28 )
WorkStation:HP ProLiant ML110 G7 (length = 32 )
Workstation: DELL PRECISION T7500 (length = 33 )
中古サーバー機にはどのようなパソコンを選んだ方が良いのか? (length = 29 )
コメントを残す コメントをキャンセル (length = 18 )実際のURLのH1からH3タグの3つの「見出しタイトル」をすべて取り出すことができます。
各「見出しリスト」の順番は記事の既出順です。ただH3タグがどのH2タグに関連しているかはこのプログラムではわかりません。
カッコ内「(length= )」の記載は、それぞれのタイトルの文字数になります。
SEO解析への応用
ブログを書くときには、ページ内にキーワードを入れ組むことはSEO対策で重要な要素の1つです。今回利用した記事タイトルには、Googlebotに検索されやすいように必要なキーワード入れ込んでおいたものです。
SEO対策にどのようにキーワードをいれるかは以下の記事をご参考にしてください。

簡単ではありますが、今回ブログ記事のH1からH3タグのタイトルにキーワードとなるものがどんなものか、そのキーワードがどれだけ含まれているか以下で解析をしてみます。
以下のPythonの解析結果は
本ブログサイト、URL=https://wisenetwork.net/archives/34
で確認してみました。
H1の見出しは文字数がすくないので、H2とH3を加えたすべての文章を統合して、「単語を分解」しキーワードの回数をPythonで統計解析した結果を示します。
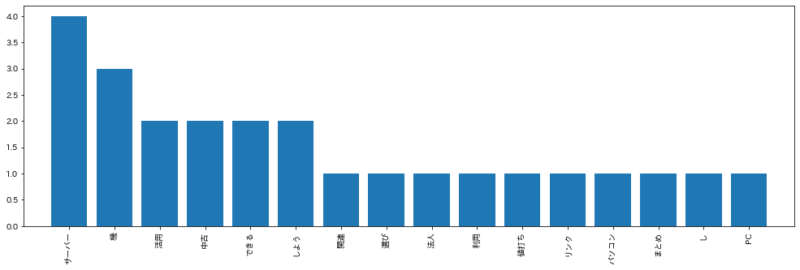
H2見出しワード(横軸はキーワード、縦軸はキーワード数)
H3見出しワード(横軸はキーワード、縦軸はキーワード数)
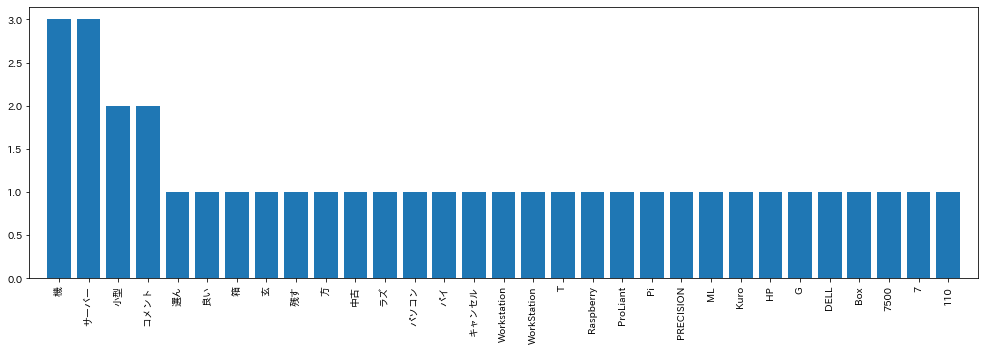
この結果から、「サーバー」「中古」「パソコン」で検索ワードが多いです。実際のGoogle consoleで出てくるキーワードもこれと同じものになっていました。
一方で、「機」とか「小型」とか「コメント」等は一般ワードに含まれているようなのでGoogleもキーワードとしては認識されていません。
このようにキーワードの頻度を確認することで既存のサイトが、
どのキーワードで勝負しようとしているのか?
キーワードの使用回数・頻度
などの情報を確認することができます。今回はタイトル文字数が少ないため解析するまでもないところがありますが、記事量が多いサイトは、タイトル・見出しも増えるため、このような解析は役に立つと思われます。
まとめ
- スクレイピングは、WEBサイトのHTMLページ内から必要とする情報を抽出する方法です。
- ✔ Pythonでスクレイピングするには「Beautiful Soup」モジュールを利用する。
- ✔ タイトル・見出しを抽出することにより該当記事の「キーワード」とその「頻度」を確認できる。
次回の記事をご期待下さい。どうぞよろしくお願いいたします。
関連リンク


コメント